

浅谈红队基础设施架构和配置

导语:最近有很多关于红队基础设施的现代战略的讨论。
最近有很多关于红队基础设施的现代战略的讨论。每一种实现都有很大的不同,但是我们希望能够提供一些深入的信息,特别是关于我们团队如何处理命令和控制的挑战。 这反映了我们所犯的许多错误,比如深夜记录的文档,当前正在进行的研究,以及我们每天使用的现实世界的解决方案。
一点理论
在寻找最佳解决方案之前,我们首先需要清楚地说明我们的目标。 每个操作的细节都是独一无二的,但是我们觉得下面的内容是对红队的一个很好的概括。
· 提供可靠的工具通讯
· 混淆和伪装,以充分避免检测
· 确保操作数据不被篡改和提取
· 最大化动作吞吐量
有些人可能熟悉汽车文化中的一句流行格言: “快速、可靠、廉价。” 选两个吧。” 这些目标在不同的方向上相互冲突,使我们的问题... ... 嗯... ... 成为了一个问题。 例如:
· 最大吞吐量可能依赖于不可靠的协议或系统
· 保护数据可能涉及潜在的通信路径
· 充分的伪装可能会减少协议选项
你还将注意到,我们目标的优先级是不同的,取决于操作的每个阶段。 在某些方面,我们可能会优先考虑隐形、吞吐量或可靠性。 正是基于这种洞察力,我们得出了第一个结论: “根据目的将你的基础设施进行分类”。 我们在黑暗面行动课程(Dark Side Ops)中大力宣扬这一点,对某些人来说可能已经过时了,但它仍然是真理。 我们的特殊类别看起来像这样:
· 阶段0(分段)-网络钓鱼和初始代码执行
· 阶段1(持久性)——维护对环境的访问
· 阶段2(交互式)——主动进行漏洞利用、枚举和权限升级
· 阶段3(渗出)-数据提取及影响
这种分段可以用来优化基础设施的一切:流量策略、代码设计、协议选择等等。 详细信息不在本文的范围之内。
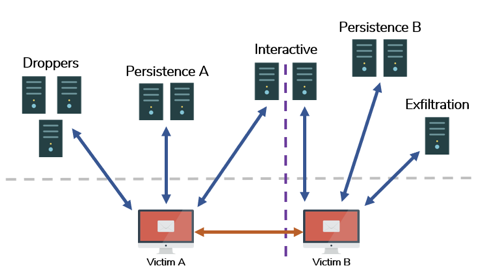
分段基础设施关系图
分段还提供了固有的弹性,允许在不影响整个系统的情况下对基础设施进行独立的妥协。 我们不希望发现任何单一的 C2域、有效载荷或工具包来危及整个操作。
像任何优秀的系统工程师一样,我们必须假设在每个阶段都会发生破坏。 你的域名会被拉黑,你的服务器会瘫痪,你的回调会被阻止。 每个阶段的基础设施设计应该是健壮的,包括备用、检查和恢复。 一般来说,拥有“更多”的一切(具有复杂性)是一个良好的开端: 多域名、多协议、多工具等等。 所有这些都伴随着设计系统的真正挑战,但始终让你的核心目标成为指南。
堡垒
现在最具攻击性的基础设施包括在你的控制之下(或部分控制之下)从远程端点路由通信。 这可能是一个 VPS,无服务器端点,或被入侵的 web 主机。 我们喜欢称这些资产为“堡垒”。
最佳实践是仅使用一个堡垒来捕获流量,而不是直接存储数据,然而,每个团队都需要对外部基础设施端点进行自己的安全评估。 我们有一个内部网络边界,我们希望在解密、处理或存储之前访问所有数据。 在这里,我们为了更好的安全性而牺牲了流量路由的复杂性。
我们还有许多分布在供应商和其他地区的堡垒。 这种多样化是我们前面提到的阶段划分的一个要求,但也有助于提供我们需要的弹性。 这意味着多个供应商、服务器、 CDN、域名等等。 我们喜欢在一个集中的 wiki 中保持对所有事情的跟踪,以便于参考。
DevOps
一旦我们的资产数量变得相当庞大,我们就开始寻找 DevOps 解决方案,任何人都会这么做。 最初,我们走的是 Ansible 这条路,创建了一个集中管理服务器,用于分散我们所有不同的基础设施。 我们首选 Ansible,主要是因为它的无代理能力,只需要 SSH 访问来进行管理。 它执行工具安装、路由配置、证书生成、加固、依赖安装等。 我们已经看到了很多成功的案例,我们的 VPS 将时间从几个小时提升到10-15分钟。 这一成功得到了我们行业中其他人的响应,他们用自己选择的解决方案(Chef、Puppet、Terraform等)执行类似的管理。
然而,我们从来没有成为过 Ansible 的专家,并且不断地为我们次优的执行付出低廉的代价。 我们也看到了对完整 DevOps 工具的需求减少,因为我们已经过渡到了需求更少的简化堡垒。 尽管如此,对于足够多样化的基础设施来说,某种形式的 DevOps 是绝对必须的。 事实上,如果你觉得不需要自动化来管理基础架构,那么你可能需要更多的自动化。
隧道
随着你的堡垒配置,流量路由本身确实是一个优先项目。 更受欢迎的选择包括:
· Socat——易于使用,但在操作系统中比我们想要的要更麻烦。 当试图同时支持多个端口时,它也可能变得复杂
· IPTables ——正确配置比较棘手,但是非常强大,几乎没有依赖项
· 反向代理——在第7层提供高级选择性路由,但需要端点上的软件、证书和配
作为我们的堡垒,我们喜欢使用 IPTables。 这在一定程度上是因为我们喜欢把堡垒看作是我们内部运营网络的最简单扩展。 任何高于第4层的内容都会使配置复杂化,并引入新的依赖关系。 说到这里,我们还在前面的平面上使用了一个反向代理,类似于两阶段的隧道设置。 我们的设置目前看起来像这样:
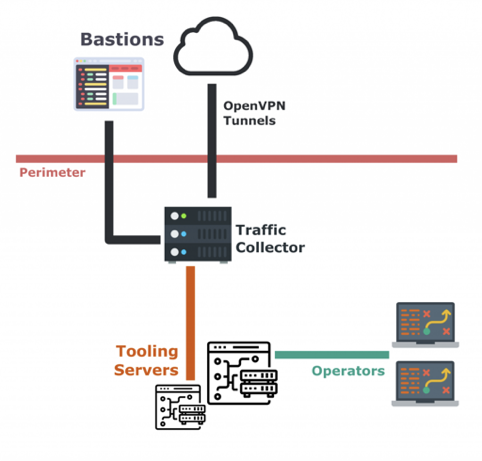
流量采集图
我们的操作网络中有一个流量采集器,它创建到公共可访问的堡垒的 OpenVPN 连接。 使用这些隧道 + IPTables,流量从公共域名/ IP 路由到惟一的内部本地隧道接口。 我们使用它在采集器上的公共 IP 地址(1.2.3.4)和它们的隧道等效 IP (10.8.1.42)之间创建一个映射。 这里的一个替代方案是使用 NAT 和端口映射来降低静态复杂性,但是这样就很难对每个可能的目标端口都通用地处理流量(我们喜欢这样做)。
在此过程中,我们还执行路由操作,以避免 IPTables 在此场景中通常使用的源转换(SNAT)。 对于不支持 x-forwarded-For 等选项的协议,我们需要跟踪客户端 IP,以便进行筛选、跟踪等。 对于这个问题,业界有一个称为 PROXY 协议的替代解决方案,它允许包装第四层流量,并在操作和路由期间维护原始数据包信息。 我们发现这个解决方案后,已经开始我们的建设,并最终决定不重新设计。
下面是 DNAT 入站流量通过 VPN 隧道的一个例子:
iptables -t nat -A PREROUTING -d 1.2.3.4 -j DNAT --to-destination 10.8.1.42
为了使返回的流量返回到正确的接口,我们可能还需要执行一些基于策略的路由操作(假设你有多个公共接口) :
ip route add default via 1.2.3.4 dev eth1 table 100 ip route add 10.8.1.0/24 dev tun0 table 100 ip rule add from 10.8.1.42 lookup 100
这将导致从流量采集器返回的任何流量使用新的路由表(100)。 在这个新表中,我们为首选的公共 IP 和 VPN 网络的知识添加了一个默认路由。 我们将为每个处理流量的公共接口提供一个单独的表(比如一个具有多个 ENI 的 EC2实例)。 这将在我们的堡垒上的每个外部IP与OpenVPN隧道另一端的内部IP之间创建映射。
Nginx
随着我们的隧道建设完成,我们现在可以将所有的流量发送到我们周边的服务器上。 这个服务器可以是一个“全局工具服务器” ,但是考虑到我们的工具包的多样性和配置的复杂性,这有点不可行。 相反,我们将在流量路由中实现第二阶段,即流量采集器。 这和你看到的其他路由没什么不同,我们决定使用 Nginx 做这个工作,有几个不同的原因,如下:
· Nginx 得到了良好的支持,并提供了许多插件、特性、选项和项目
· Nginx 是仅有的能够执行第4层(TCP/UDP)流的7层代理之一。 这对于使用 DNS 隧道或混淆的第7层协议之类的工具非常重要
· Nginx 支持一种“透明代理”模式,允许你在没有 SNAT 的情况下转发流量,我们仍在努力避免这种情况
我们也考虑过 Envoy ,它让人好奇,但该项目仍然是相当新的项目。 在我们深入讨论之前,让我们介绍一下配置 Nginx 流量采集器的具体目标:
· 回调函数必须经过适当的路由
· 域名必须有合法的 SSL 证书
· 每个域名必须包含合法的 HTML 内容
· 我们不能在传输过程中丢失真实的客户端 IP 信息
在 Nginx 中,有两种主要的流量重路由方法: 反向代理和流模块。 我们将首先讨论这两者的一般优点和缺点,然后再讨论我们的具体实现。
反向代理
反向代理接收一个 HTTP 请求,有选择地修改或检查数据的各个方面,然后将其发送到指定的 web 服务器。 我们可以使用这个第七层实现智能化:
· 动态地检查 HTTP 流量,并动态地将流量路由到不同的监听站(LP)或内容服务器
· 简化 SSL 管理,并为所有证书使用单个服务器
· 动态修改 / 添加 HTTP 头和内容,以便为后端服务器提供上下文
使用反向代理的主要缺点是功能依赖于 HTTP/S。
流模块
简单来说,Nginx 流模块基本上就是端口重定向,就像 socat 一样。 类似于反向代理,你可以指定负载均衡和故障转移主机。 我们失去了第7层的智能化,不能在转发前限定回调。 然而,我们可以使用支持 TCP/UDP 的任意协议来路由流量。 这是 Nginx 在某种程度上的独特之处,关于这一特性的公开讨论比较少,但配置简单,对我们的目的来说似乎运行良好。
实现
在我们的生产设置中,我们使用了这两种路由选项。 让我们从基本配置开始,逐步完成特性集,直到我们得到所需的一切。 首先,一个基本的反向代理配置路由到我们的工具服务器:
http {
server {
listen 10.8.1.42:80;# Tunnel bind IP
location / {
proxy_set_header Host $host;
proxy_set_header X-Forwarded-For $remote_addr;
proxy_pass http://172.16.1.20; # Tooling server
}
}
}接下来,我们需要添加 SSL 支持。 我们希望在 Nginx 服务器上断开 SSL,只转发 HTTP 通信。 这有助于简化工具服务器的配置。
http {
server {
listen 10.8.1.42:80; # Tunnel bind IP
listen 10.8.1.42:443 ssl;
ssl_certificate /etc/letsencrypt/live/domain.com/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/domain.com/privkey.pem;
location / {
proxy_set_header Host $host;
proxy_set_header X-Forwarded-For $remote_addr;
proxy_pass http://172.16.1.20; # Tooling server
}
}
}我们通常使用 certbot 生成证书:
certbot certonly -d mydomain.com –standalone
所有到公共 IP 的流量现在都被路由到我们的工具服务器,但是我们也希望将不必要的 web 流量路由到一个单独的内容服务器。 这有助于稳定 LP 并减少被动负载。 为了实现这一目标,我们确定了两个策略:
· 只有当 LP 用于交互操作、数据外泄等时,才能临时将流量转发到 LP
· 只转发与我们的工具相关的流量(例如文件下载器、持久性等等)
对于解决方案 A,我们可以使用 Nginx 的上游池机制。 当可用时,流量将被转发到主上游地址(工具服务器) ,否则,它将被路由到备份地址(内容服务器)。 Nginx 将自动检测主上游地址何时可用,并相应地转发请求。
http {
upstream pool-domain-com {
server 172.16.1.10:80 backup; # Content Server
server 172.16.1.20:80; # Tooling server
}
server {
listen 10.8.1.42:80; # Tunnel bind IP
listen 10.8.1.42:443 ssl;
ssl_certificate /etc/letsencrypt/live/domain.com/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/domain.com/privkey.pem;
location / {
proxy_set_header Host $host;
proxy_set_header X-Forwarded-For $remote_addr;
proxy_pass http://pool-domain-com;
}
}
}要实现解决方案 B,可以将 Nginx 配置为基于 GET 或 POST 变量、 HTTP 头或请求的 HTTP 页面路由请求。 例如,下面的配置将把对/API的代理请求反向到IP地址172.16.1.30。所有其他请求将被转发到pool-domain-com上游池。
http {
upstream pool-domain-com {
server 172.16.1.10:80 backup; # Content Server
server 172.16.1.20:80; # Tooling server
}
server {
listen 10.8.1.42:80; # Tunnel bind IP
listen 10.8.1.42:443 ssl;
ssl_certificate /etc/letsencrypt/live/domain.com/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/domain.com/privkey.pem;
location /api { # Additional tooling endpoint
proxy_set_header Host $host;
proxy_set_header X-Forwarded-For $remote_addr;
proxy_pass http://172.16.1.30/;
}
location / {
proxy_set_header Host $host;
proxy_set_header X-Forwarded-For $remote_addr;
proxy_pass http://pool-domain-com;
}
}
}基于 HTTP 标头和 URL 参数的路由要复杂一些。 我们不会详细讨论这个问题,但是为了给你指出正确的方向,请查看重写(rewrite)模块中的“if”指令文档。 下面是基于特定用户代理字符串的自定义路由规则的示例。 $http_user_agent 是一个标准的 Nginx 配置变量。 同样的逻辑也适用于其他配置变量。 这个文档提供了额外的细节。
location / {
if ($http_user_agent ~ MSIE) {
proxy_set_header Host $host;
proxy_set_header X-Forwarded-For $remote_addr;
proxy_pass http://pool-domain-com;
}
}现在我们的反向代理已经配置好了,我们需要添加对 DNS 回调的支持。 我们只需在 HTTP 配置部分的上方放置一个流指令,详细说明绑定端口和目的地。 值得注意的是,流指令仍然像 HTTP 配置一样支持上游池和透明绑定。 以下将把 TCP 53 全局重定向到172.16.1.20。
stream {
server {
listen 53 udp;
proxy_pass 172.16.1.20:53; # DNS LP
}
}
http {
...
}经验教训
在生产环境中部署安装程序后不久,我们遇到了以下错误。
2099/01/02 21:08:47 [crit]: accept4() failed (24: Too many open files)
这是因为 Linux 对用户可以打开的文件数量设置了软限制和硬限制。 我们只需要通过修改如下所示的配置来增加操作系统级别和 Nginx 内部的限制。
在 /etc/security/limits.conf 文件中添加以下内容:
nginx soft nofile 200000 nginx hard nofile 200000
在 /etc/nginx/nginx.conf 文件中添加以下内容:
worker_rlimit_nofile 200000;
除此之外,还有一些其他的配置项值得一提:
· 请求最大内容尺寸(client_max_body_size)
· GZip 支持 (gzip)
· 保持活动超时(keepalive_timeout)
· SSL 配置 (ssl_protocols)
工具集成(签入 / 签出)
随着我们前面的 Nginx 配置完成,我们希望将一些最后的工作放到工具集成中。 理想情况下,我们需要一种临时捕获和释放流量流的机制。这将允许我们编写能够加载、接管可用流量流、将其用于操作、然后将其释放回池中的工具。 其中一个集成就是我们所说的“Op工作站”。一般来说,这只是操作人员用于交互操作的内部VM。当然,我们在这些观测站选择的工具是 Slingshot。
为了构建上面的解决方案,我们将一些基本的 DNS 服务与辅助 IP 寻址结合起来。 首先,假设我们有以下活跃的流量流:
banking.com -> Bastion A [1.2.3.4] -> Nginx [10.8.1.2] -> Content Server [172.16.1.10] health.org -> Bastion B [5.6.7.8] -> Nginx [10.8.1.3] -> Content Server [172.16.1.10] support.com -> Bastion C [9.5.3.1] -> Nginx [10.8.1.4] -> Content Server [172.16.1.10]
使用下列Nginx上游池:
upstream pool-banking-com {
server 172.16.1.10:80 backup; # Content Server
server 172.16.1.20:80; # Operations
}
...
upstream pool-heath-org {
server 172.16.1.10:80 backup; # Content Server
server 172.16.1.30:80; # Operations
}
...
upstream pool-support-com {
server 172.16.1.10:80 backup; # Content Server
server 172.16.1.40:80; # Operations
}Nginx 检测到所有操作的 IP 地址都没有被使用(无法访问) ,因此将这三个域名的所有流量路由到我们的内容服务器。 这些域名目前处于“被动模式” ,只是提供内容和看起来正常。 如果我们想让一个新的 VM/工具 开始捕获流量,我们只需为主机分配一个特定上游池的“操作”地址。
# Start collecting traffic for banking.com ifconfig eth0:0 172.16.1.20 netmask 255.255.255.0
简单易用,但是特定的工具如何知道当前可用 IP 的列表以及它们映射到哪个域名? 我们花了相当多的时间来探索不同的解决方案。 Nginx 公开了一些我们的工具可以用来查询当前配置(redx 或 Nginx Pro)的 API。 我们可以有一个集中的 SQL 数据库,其中包含所有的活动域名。 我们可以使用某种 DHCP 服务来发布 / 更新 IP。 所有这些服务通常都是昂贵的,无论是技术上还是物理上。
最终我们选择了 DNS,即 OG 主机名数据库。 具体来说,我们选择了与本地主机文件配对的 dnsmasq 。 集合服务器很容易更新 / 修改记录,并且可以通过简单的域传送检索所有域名。 我们还可以添加文本标记,以根据目的和上下文划分域。
设置相对简单,大多数安装指南都能让你达到90% 的效果。 我们只需要做一些小的调整,将服务链接到一个静态主机文件,并允许从任何 IP 进行域传送。
addn-hosts=/root/records @ Our host file auth-sec-servers=0.0.0.0 auth-zone=operations.local domain=operations.local log-queries
我们的 /root/records 文件如下所示:
172.16.1.10 content 172.16.1.20 stage2-banking-com 172.16.1.30 stage2-health-org 172.16.1.40 stage1-support-com
我们在这些域名前面添加了一个阶段标识符,以允许不同的工具只查询应用于它们的域名。 查找是一个简单的 AXFR,然后进行一些验证和选择。
$domains = dig axfr @ns1.operations.local operations.local | grep stage2 # Ping/Nmap to see which are in use # Prompt the operator for a selection
总结
总之,我们设计了一种灵活、安全和可伸缩的方法来管理来自多种资源的多个回调。 这种方法简化了 SSL 证书管理(对于30多个域名来说,这是一个非常头疼的问题) ,以及需要启动和配置额外的外部基础设施,同时在内部网络中维护所有原始的 C2数据。
最终,基础设施提供了达到目的的手段。 它支持和增强了我们的运作,是任何一个好的红队的基础。 就像任何建筑一样,如果地基出现问题,那么所有的建筑最终都会变成一堆瓦砾。
我们希望在这里提供足够的信息,以激发你的兴趣,并激励你将你的基础设施提升到一个更好的水平。 我们欢迎反馈和新的想法。
参考资料
· https://www.nginx.com/resources/wiki/start/topics/depth/ifisevil/
· https://cheat.readthedocs.io/en/latest/nginx.html
· https://docs.nginx.com/nginx/admin-guide/web-server/reverse-proxy/
· https://docs.nginx.com/nginx/admin-guide/security-controls/securing-http-traffic-upstream/
· https://gist.github.com/v0lkan/90fcb83c86918732b894

发表评论











 提供云计算服务
提供云计算服务