

Cloudflare的HTML解析历史(上)

导语:HTML解析中的漏洞

什么是HTML流量重写器?
HTML流量 重写器接受HTML字符串或字节流输入,将其解析为令牌或任何其他结构化中间表示(IR),例如抽象语法树(AST)。然后,它在转换回HTML之前对标记执行转换。这就提供了在处理字节时修改,提取或添加到现有HTML文档的功能。将其与标准的HTML树解析器进行比较,后者需要检索整个文件以生成完整的DOM树。基于树的重写器将花费更长的时间来交付第一个处理的字节,并且需要更多的内存。

HTML重写器
例如你拥有一个拥有很多历史内容的大型网站,现在希望通过HTTPS来提供该网站。你将很快遇到通过HTTP提供资源(图像、脚本、视频)的漏洞,因为这种“混合内容”打开了一个安全漏洞,浏览器将警告或阻止这些资源。这意味着,更新网站每个页面上的每个链接可能很困难,甚至不可能。使用HTML流量重写器,你可以选择任何HTML标记的URI属性,并将任何HTTP链接更改为HTTPS。研究人员在2016年构建了此功能,即自动HTTPS重写以解决客户的混合内容问题。
下文,我将详细介绍如何从在HTML页面中查找电子邮件地址的简单想法开始,以构建几乎符合规范的HTML解析器,然后到匹配虚拟机的CSS选择器的旅程。
在边缘重写
通过Cloudflare重写内容时,我们不想影响网站性能。设计HTML流量重写器的平衡在于,通过保留尽可能少的信息,同时保留重写匹配标记的能力,来最大程度地减少响应字节流中的暂停。
与浏览器中使用的HTML解析器相比,要求的差异包括:
输出延迟
对于浏览器来说,文档对象模型(DOM)是解析过程的最终目的,但在本例中,我们必须解析,重写并序列化回HTML。对于Cloudflare的反向代理,边缘服务器上的任何内容处理都会导致服务器与眼球之间的延迟。要最小化HTML处理的延迟影响,这涉及解析,重写和序列化回HTML。在所有这些阶段中,我们都希望尽可能快地将延迟最小化。
什么是边缘服务器
随着互联网及其应用的快速发展,绝大多数企业都建立自己的网站,增强对外联络,加速业务流程,客户对网站系统访问的响应时间,网站内容以及所提供服务的可靠性,即时性等要求也越来越高,使得以单台服务器来支撑整个网站的系统已无法满足客户需求,取而代之的是采用两到三层架构的一组服务器.第一层是跟用户直接发生联系的前端服务器,也称为边缘服务器。
边缘服务器为用户提供一个进入网络的通道和与其它服务器设备通讯的功能,通常边缘服务器是一组完成单一功能的服务器,如防火墙服务器,高速缓存服务器,负载均衡服务器,DNS服务器等。第二层是中间层,也称为应用服务器,包括Web表现服务器,Web应用服务器等.第三层是后端数据库服务器。
解析器的加载量
通常情况下,浏览器很少需要处理大小超过1Mb的HTML页面,并且平均页面加载时间最多约为3s。 HTML解析不是页面加载过程的主要瓶颈,因为浏览器在运行脚本和加载其他关键用户资源时会被阻塞。我们可以粗略估计,对于浏览器的HTML解析器来说,大约3Mbps的加载量是可以接受的。在Cloudflare,每个CPU拥有数百兆的流量,因此我们需要一个解析器,其速度要快一个数量级。
内存限制
比如简单的HTML标记在浏览器中打开时,将消耗大量系统内存,最后终止浏览器选项卡(解析器将消耗所有这些内存):

不幸的是,即使对于HTML流量重写,也不可避免地需要缓冲部分输入。考虑以下两个HTML代码段:


当在HTML页面末尾遇到HTML时,这些看似相似的HTML片段将被完全区别对待。第一个片段将被解析为开始标记,第二个片段将被忽略。仅通过查看' < '字符后的标记名,解析器无法确定是否找到了开始标记。它需要遍历搜索结束“>”的输入以做出决定,缓冲中间的所有内容,以便稍后将其作为开始标签令牌发送给使用者。
这一要求迫使浏览器在最终放弃内存不足漏洞之前无限期地缓冲内容,在本文的示例中,我们无法花费数百兆的内存来解析单个HTML文件(实际的限制甚至更严格,甚至每个请求使用十几KB都是不可接受的)。就内存使用而言,我们需要比其他实现复杂得多,并且可以优雅地处理所有提供的内存容量不足以完成解析的情况。
v0:随机(Ad-hoc)解析器
查找和模糊电子邮件
2010年,Cloudflare决定提供一项功能,以阻止流行的电子邮件抓取工具。这种保护的基本思想是查找和模糊页面上的电子邮件,然后使用注入的JavaScript代码在浏览器中将其解码回去。听起来很简单,对吧?你搜索任何看起来像电子邮件的东西,对其进行编码,然后使用一些JavaScript魔术对其进行解码,然后将结果呈现给最终用户。
但是,即使这样看似简单的任务也已经需要解决几个问题。首先,我们需要定义什么是电子邮件。实际上,甚至臭名昭著的RFC都涵盖了整个RFC,实际上,它已经过时且不完整,因为新RFC添加了许多有效的电子邮件构造,包括Unicode支持。现在,让我们关注一个更高层次的问题:转换流量内容。
来自网络的内容以数据包的形式出现,这些数据包必须由我们的服务器缓冲并解析为HTTP。你无法预测内容的分割方式,这意味着你始终需要对其中的某些内容进行缓冲,因为要替换的内容可以存在于多个输入块中。
假设我们决定使用简单的正则表达式,比如' [\w.]+@[\w.]+ '。如果通过的内容包含电子邮件“test@example.org”,它可能被分成以下几块:
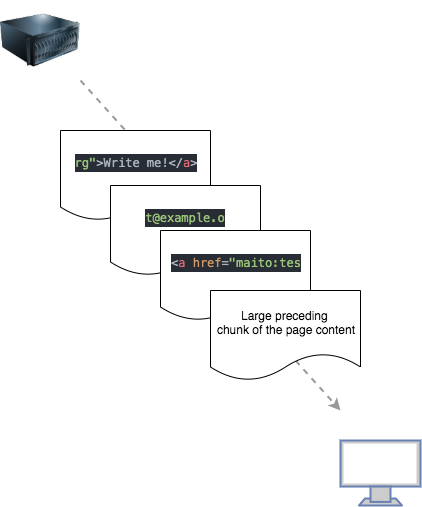
为了保持首字节时间(TTFB)和一致的速度,我们希望确保在确定前一个块不适合用于替换时立即释放它。
最简单的方法是将正则表达式转换为状态机或有限自动机,尽管你可以手动完成此操作,但最终将获得难以维护且易于出错的代码。相反,选择了Ragel将正则表达式转换为有效的本机状态机代码。 Ragel除了遍历状态机外,不会尝试缓冲或做其他任何事情。它提供的语法不仅可以描述模式,还可以将自定义操作(以宿主语言编写的代码)与任何给定状态相关联。
在本文的示例中,我们可以通过缓冲区,直到匹配电子邮件的开头。如果我们随后发现该模式不是电子邮件,则可以在该模式停止匹配后立即退出缓冲。否则,我们可以检索匹配的电子邮件并将其替换为新内容。
要将模式转换为流解析器,我们可以记住电子邮件的可能开头的位置,除非已将其丢弃或由当前输入的末尾替换,否则将未处理的部分存储在永久缓冲区中。然后,当出现一个新块时,我们可以对其进行单独处理,从Ragel记住自己的状态恢复,但随后使用缓冲的块和一个新块来发出或进行模糊。
现在,我们已经解决了在文本中匹配电子邮件模式的问题,我们需要处理一个事实,即它们需要在页面上进行模糊,这是第一次引入HTML“解析”的提示。
我将“解析”放在引号中,因为电子邮件过滤器(模块的名称)并没有实现整个解析器,而是试图复制整个HTML语法,而是添加了自定义的Ragel模式,仅用于跳过注释以及不应模糊电子邮件的标签。
这是一种合理的方法,尤其是在2010年,HTML5规范发布的四年之前,当时所有浏览器都有自己独特的HTML处理方法。但是,你可以想象,这种方法无法很好地扩展。与此同时,新的特性开始添加,这也需要动态修改HTML(比如自动插入谷歌分析脚本),现有的模块似乎是最好的地方。它发展到能够处理越来越多的标记、操作和语法边缘情况。
在2011年,Cloudflare决定还添加缩小功能,即使用户自己没有使用缩小功能也能加快其网站的速度。为此,我们决定使用现有的流量压缩器——jitify。它已经具有NGINX绑定,这使其非常适合集成到现有管道中。
不幸的是,就像当时的大多数其他解析器以及我们上面描述的那样,它具有自己的HTML,JavaScript和CSS处理规则,这些规则并不精确,而是试图尽最大努力解析内容。这导致我们拥有两个不兼容的独立流解析器,并且可能单独或组合生成漏洞。
v1:符合HTML5规范的解析器
多年来,工程师一直在向不断增长的状态机中添加新功能,同时修复了由于语法实现不精确,各种解析器之间的冲突以及功能本身存在的问题而引起的新漏洞。
接下来,我将描述研发者是如何从规范状态机开始构建符合HTML5的解析器。仅使用此状态机,就应该直接构建解析器。你可能已经知道,从历史上看,HTML的解析并非十分严格,这意味着在不破坏现有实现的情况下,解析时需要构建实际的DOM。这对于流量重写器是不可能的,因此开发了解析器反馈的模拟器。就性能而言,最好不要做任何事情。然后,我们描述了为什么重写器在重写HTML时可能会变得“懒惰”而不执行昂贵的文本编码和解码,然后详细讨论了判断响应是否是HTML的难题。
HTML5
到2016年,HTML5已经为解析和兼容遗留内容和自定义浏览器实现定义了精确的语法规则,目前,所有浏览器和许多第三方实现都已经实现了它。
HTML5解析规范以状态机的形式定义了基本的HTML语法,我们已经在Ragel上有过类似用例的经验。尽管语法很复杂,但规范到Ragel语法的翻译却很简单。由于能够将regex语法与显式转换混合在一起,因此代码看起来比状态机的形式描述更简单。
HTML5解析需要一个“DOM”
为了不破坏现有的实现,HTML5被指定为针对不正确的标签嵌套、排序、未关闭的标签、缺失的属性和所有其他在旧浏览器中可能出现的问题的恢复过程。为了解决这些问题,该规范要求使用树构建器来驱动词法分析器。从本质上讲,如果没有DOM,就无法正确标记化HTML(分割为单独的标签)。
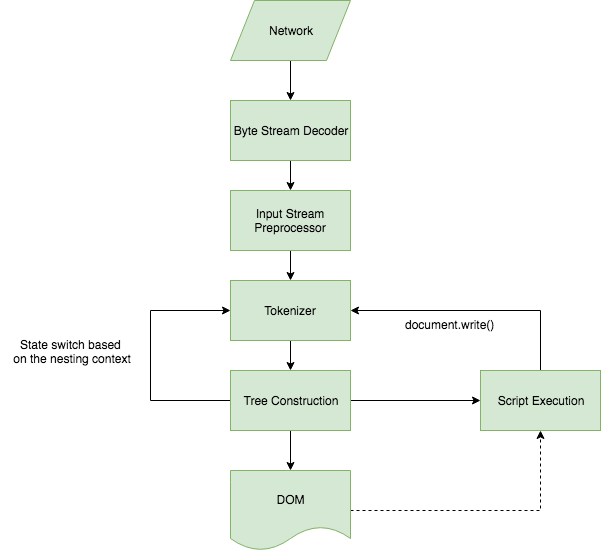
规范定义的HTML解析流程
因此,大多数解析器甚至不尝试执行流解析,而是将输入作为一个整体并生成一个文档树作为输出。如果不给页面加载增加明显的延迟,我们就无法进行流转换。
现有的HTML5 JavaScript解析器parse5已使用流量令牌生成器和重写器实现了符合规范的树解析。为了避免必须创建完整的DOM,引入了“解析器反馈模拟器(parser feedback simulator)”的概念。
树生成器的反馈机制
你可以从名称中猜到,该模块旨在模拟完整解析器对令牌生成器的反馈,而无需实际构建整个DOM,而是仅保留正确驱动状态机所需的必要信息和上下文。
在经过严格的测试并将测试运行器升级到parse5之后,我们发现这种技术适用于网络上大多数编写得很差的页面,并将其应用到LazyHTML中。
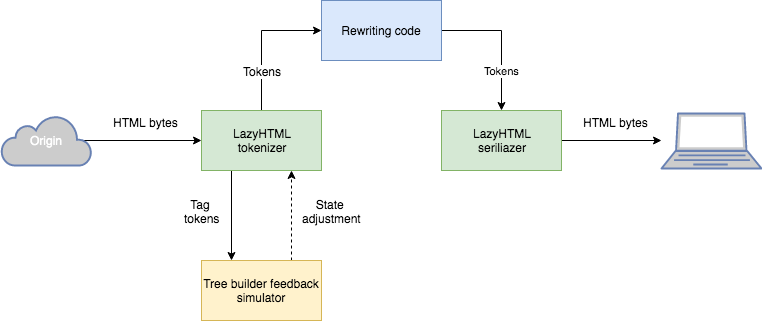
LazyHTML架构
下一篇文章,我们继续介绍可能出现的漏洞以及其中的原因,并就如何基于LazyHTML的思想构建新的流量重写器。

发表评论











 提供云计算服务
提供云计算服务